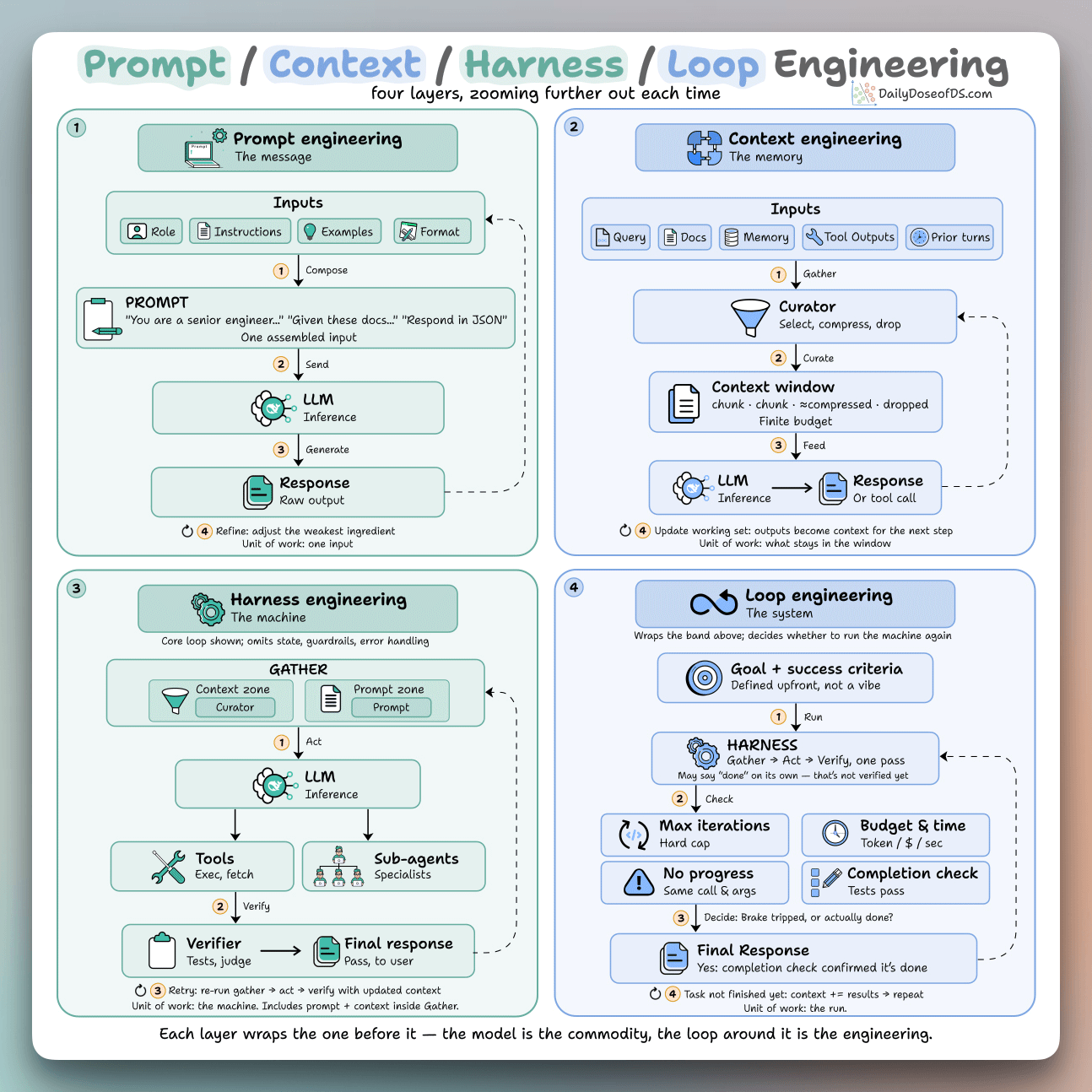
AI agents work as a while loop, but building production systems requires four layers of engineering around that core: prompt design, context management, harness code that handles tool calls and retries, and loop automation that runs many turns without human intervention. The outermost loop layer is hardest because agents cannot reliably know when they are finished, so stop conditions must be defined upfront using external signals like progress detection and schema validation.
Summaries like this, in your inbox every morning.
Sign up free →What happened
An article breaks down the engineering architecture of AI agents into four nested layers—prompt engineering, context engineering, harness engineering, and loop engineering—each wrapping around the core while-loop that defines how agents work. The outermost loop layer automates the entire run without manual prompts, setting goals and stop conditions upfront instead of writing each prompt by hand.
Why it matters
Most of the difficulty in building production agents lies outside the model itself. Getting the data clean, managing the context window, parsing tool outputs, and knowing when to stop are engineering problems that often take longer to solve than training the model. For teams building agents, this framework clarifies which layer—prompt, context, harness, or loop—needs attention when something fails.
What to watch
The loop layer introduces the hardest problem: knowing when to stop. The article notes that agents must use real signals like turn caps, token caps, no-progress detection, and completion checks—not just the agent's claim that it is done—because the tests may still fail even when the agent reports success.
No discussion yet for this article
Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
1 minute a day. The AI essentials.
200+ sources · Email / LINE / Slack