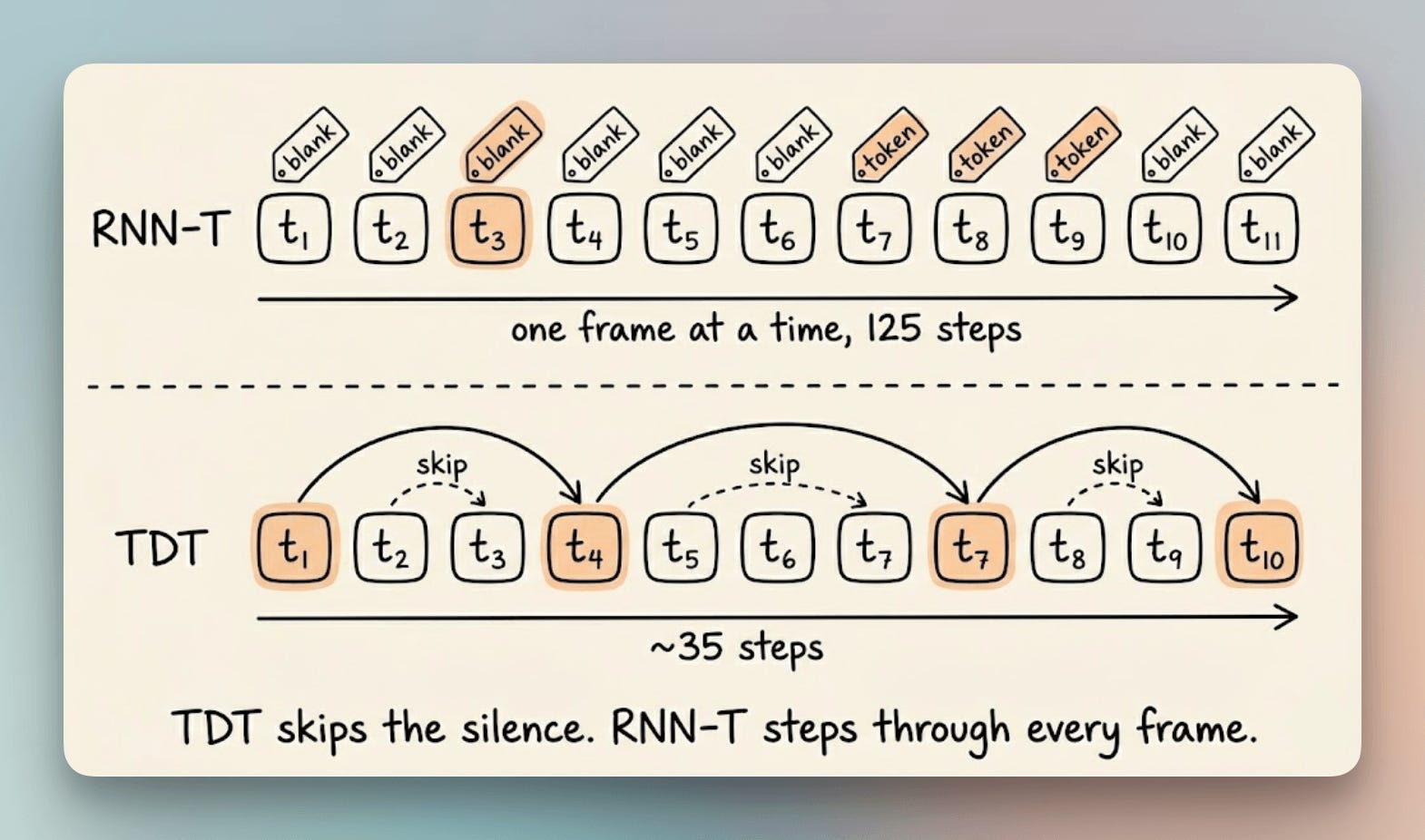
Speech recognition systems waste most of their compute on processing silence rather than actual speech, making voice agents feel slow. A new decoder called Token-and-Duration Transducer fixes this by letting the model predict how many frames to skip instead of confirming each frame one at a time, achieving up to 2.82x faster decoding while maintaining accuracy. The change requires only one extra output head on the joint network, and NVIDIA's and Speechmatics's implementations already lead industry speed benchmarks.
Summaries like this, in your inbox every morning.
Sign up free →What happened
Researchers found that speech recognition systems waste compute processing silence instead of speech. A new decoder architecture called Token-and-Duration Transducer (TDT) lets the model skip ahead through silence rather than confirming it frame-by-frame. On English speech recognition, TDT matches or beats standard models on accuracy while decoding up to 2.82x faster.
Why it matters
Voice agents feel laggy partly because traditional systems process every frame of silence one at a time. For a typical 10-second audio clip, standard decoders run about 125 sequential calls, most confirming nothing happened. Faster decoding directly improves real-time voice agent responsiveness without requiring larger models or more training data.
What to watch
NVIDIA's Parakeet TDT models now lead the Huggingface Open ASR Leaderboard on throughput (RTFx, a metric measuring seconds of audio processed per second of wall-clock time) despite using the same encoder size and training data as plain RNN-T models ranked below them. Speechmatics runs this approach in production and scored 1.07% pooled word error rate on the Pipecat voice agent benchmark across 1,000 samples.
No discussion yet for this article
Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
1 minute a day. The AI essentials.
200+ sources · Email / LINE / Slack