こういう要約が、毎朝あなたのメールに届きます。
無料で登録 →AnthropicがClaude Mythosへのアクセスを制限している。このモデルはほとんどの人間より優れたセキュリティ脆弱性発見能力を持つ
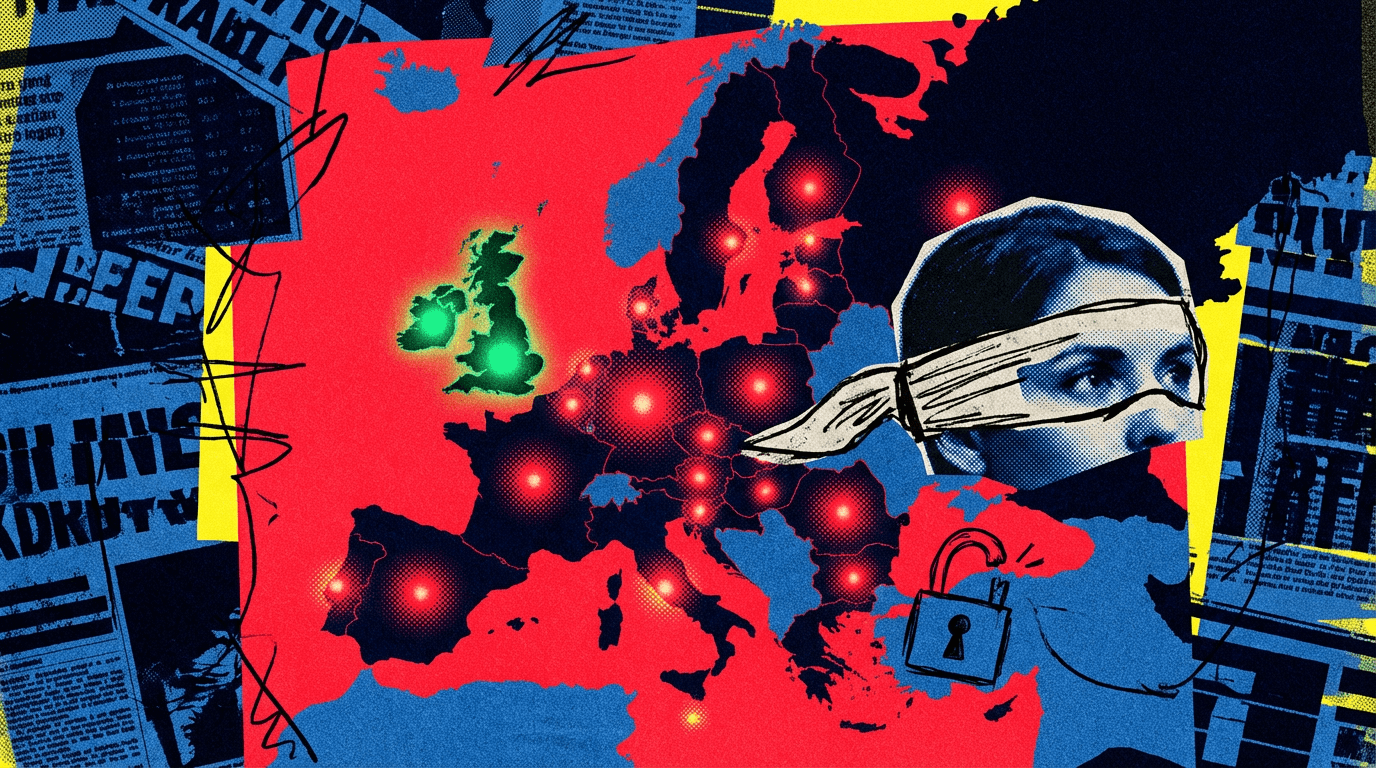
欧州当局はこのシステムにほぼ可視性がない一方で、英国は既に独自テストを実施している
この状況はEUのAI安全保障インフラの構造的問題をあらわにしており、規制当局による監視の格差が深刻化している
まだコメントがありません。最初のコメントを投稿しましょう!
ログインして議論に参加200以上のソースから厳選したAIニュースを毎日無料でお届けします。
無料で始める登録無料・30秒で完了・いつでも解除できます
毎朝1分、AIの要点だけ。
200媒体以上・Email/LINE/Slack 対応





