← 記事一覧に戻る


AMD enthusiast builds local LLM workstation achieving 120 tokens/second with Ryzen 9700X and Radeon R9700, seeking optimal model recommendations.
r/LocalLLaMA · 2026年4月20日
AI要約
- •Builder configured high-end local inference rig with AMD Radeon AI PRO R9700 (32GB VRAM) and Ryzen 7 9700X CPU paired with 64GB DDR5 RAM
- •System achieves ~120 tokens/second performance on simple prompts using Qwen3.6-35B-A3B model via LM Studio with Vulkan backend
- •Poster seeks community advice on largest compatible model architectures and whether Q4_K_M quantizations are optimal for their hardware setup
関連記事
AI関連株・マーケット
Palantir's AI technology could modernize the FAA's aging air traffic control system, which handles 45,000 daily flights but struggles with congestion and outages.
Yahoo Finance AI·2026年4月20日
AI関連株・マーケット
Broadcom's stock has surged nearly 800% over five years, driven by explosive demand for AI chips, raising questions about future growth potential.
Yahoo Finance AI·2026年4月20日
AI関連株・マーケット
Adobe launches enterprise AI agents, signaling software sector's continued relevance despite AI disruption concerns
Yahoo Finance AI·2026年4月20日
大規模言語モデルオープンソースAI
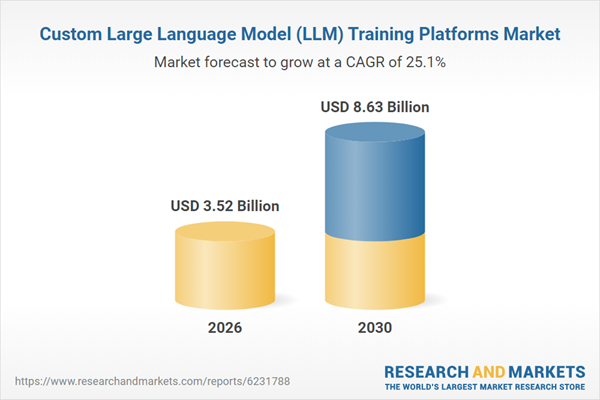
Custom LLM training platforms from AWS, NVIDIA, Microsoft, and OpenAI are positioned for significant growth through 2035, with major opportunities in domain-specific model training and secure cloud deployments.
Yahoo Finance AI·2026年4月20日
AI関連株・マーケット
Alphabet pursues custom AI chip partnership with Marvell to reduce dependence on external suppliers and boost Google Cloud efficiency.
Yahoo Finance AI·2026年4月20日
AIニュースを毎日お届け
200以上のソースから厳選したAIニュースを毎日無料でお届けします。
無料で始める