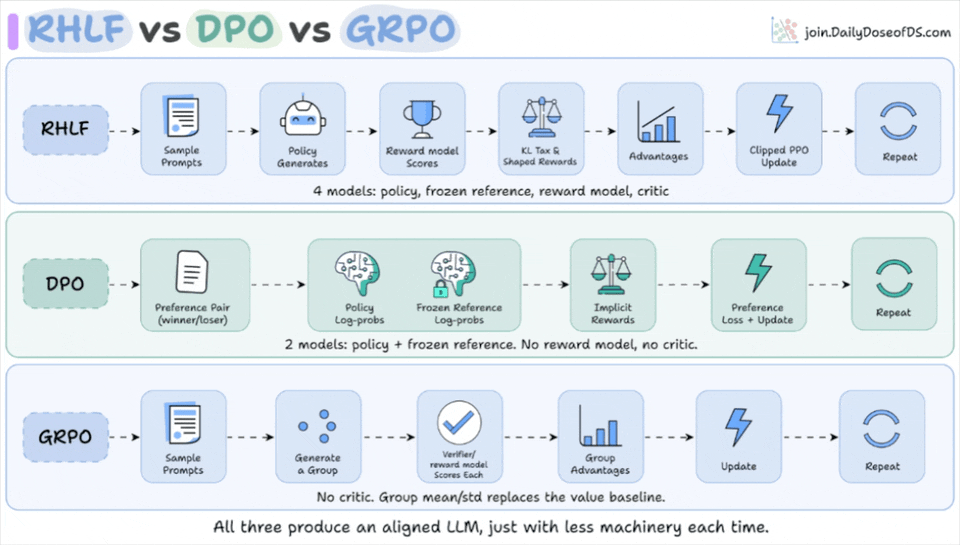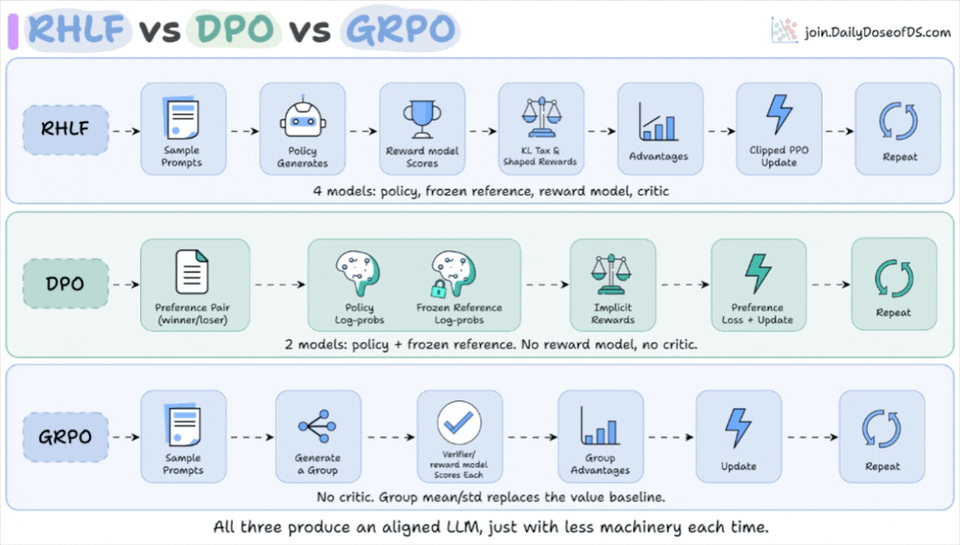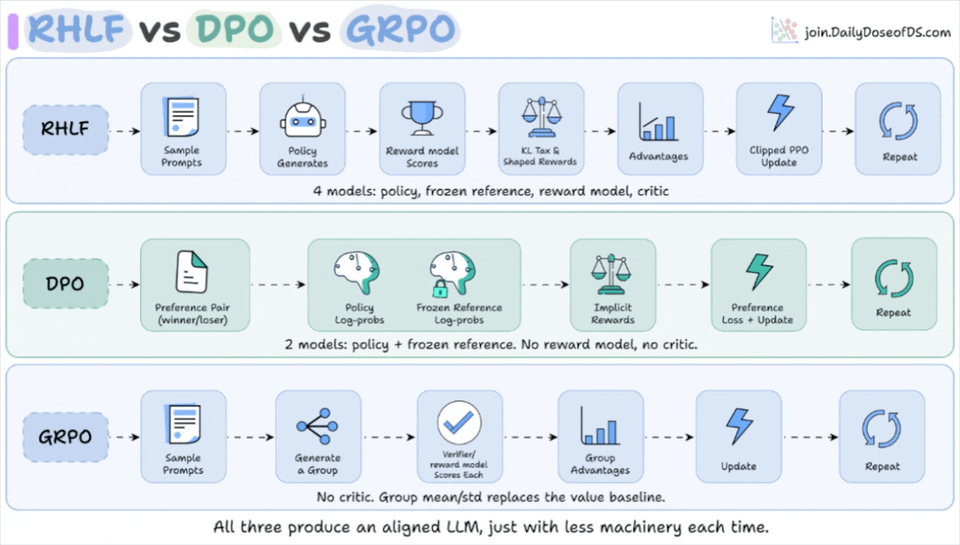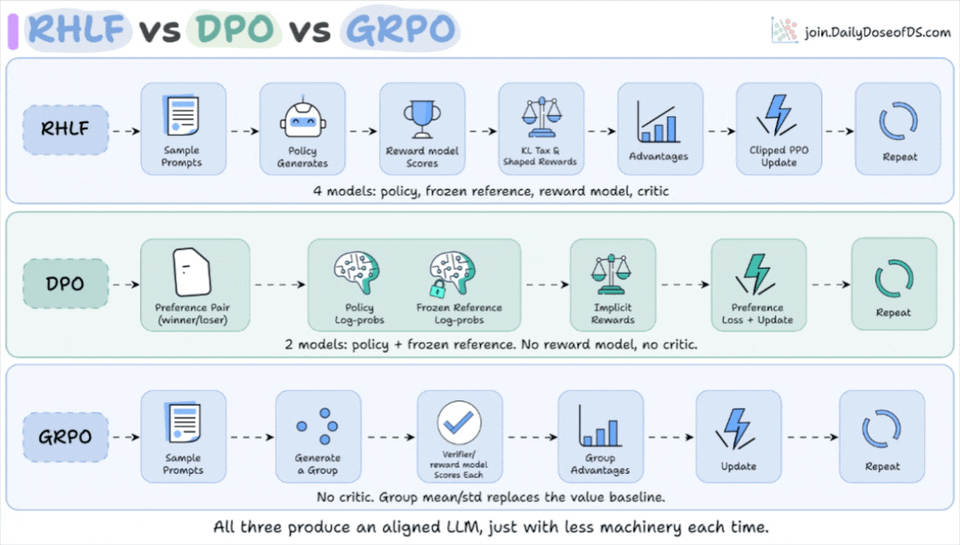
こういう要約が、毎朝あなたのメールに届きます。
無料で登録 →研究チームがGPT-5.4、Gemini 3.1 Pro、Claude Sonnet 4.6、DeepSeek-V4-Pro、Kimi-K2.6など11のモデルを検証した結果、BrowseCompベンチマーク上の高スコアの大部分が、インターネット接続なしの記憶だけで解答可能なことが判明。MiniMax M2.5は44.5%、Kimi K2.6は62%(中国語版BrowseComp-ZH)を記憶だけで達成。
検索インターフェースを残したまま確認用ドキュメントを削除すると、全モデルの性能は記憶のみの場合より低下。MiniMax M2.5は44.5%から8.0%へ、Kimi-K2.6は25.5%から2.3%へ低下。モデルの独自推論が検索クエリの半数以上を占め、関連証拠が見つかった場合でも3分の1未満の使用率。
時系列の新情報に対応した新ベンチマーク「LiveBrowseComp」(過去90日以内の事実を含む335問の人間作成問題)では、閉鎖環境テストで全モデル2%未満の精度に低下、ツール使用時でもBrowseComp結果より約25~40ポイント低下。これまでBrowseCompで上位だったGLM 5.1はLiveBrowseCompで中位に後退、底位だったDeepSeek v3.2が首位に浮上。
AIが要約して、あなたの選んだトピックだけを1日1通。LINE・Email・Slackで届きます。
登録無料・30秒で完了・いつでも解除できます
まだコメントがありません。最初のコメントを投稿しましょう!
ログインして議論に参加200以上のソースから厳選したAIニュースを毎日無料でお届けします。
無料で始める登録無料・30秒で完了・いつでも解除できます
毎朝1分、AIの要点だけ。
200媒体以上・Email/LINE/Slack 対応