
Summaries like this, in your inbox every morning.
Sign up free →AWS combined Amazon FSx for Lustre with NVIDIA GPUDirect Storage (GDS) to enable direct data transfer from storage to GPU memory, bypassing CPU and system memory. On a P5en instance with 8 NVIDIA H200 GPUs, the filesystem delivers approximately 94 GiB/s of throughput using a Persistent_2 EFA filesystem at 1000 MBps/TiB with 20 Object Storage Targets.
Traditional model loading for Llama 3.1 405B (roughly 800 GB in BF16 format) takes 10–20 minutes via CPU-bound sequential operations; the sharded GPUDirect Storage approach pre-splits checkpoints across tensor-parallel ranks, allowing all GPUs to read their shards in parallel directly into HBM over EFA, reducing unproductive load time to seconds.
Faster model loading directly improves cold start latency for new instances, autoscaling responsiveness, fault recovery speed, and cost efficiency by reducing GPU-hours consumed during loading rather than serving requests.
AI-summarized, only the topics you pick — one digest a day via Email, Slack, or Discord.
Free · takes 30 seconds · unsubscribe anytime
No comments yet. Be the first to share your thoughts!
Log in to join the discussion

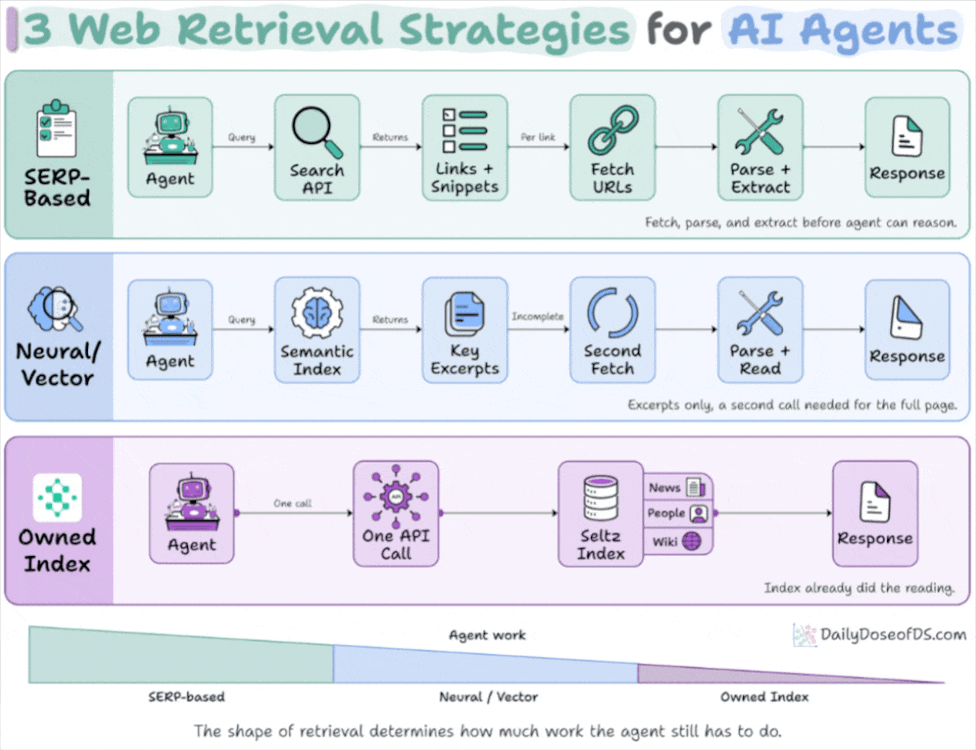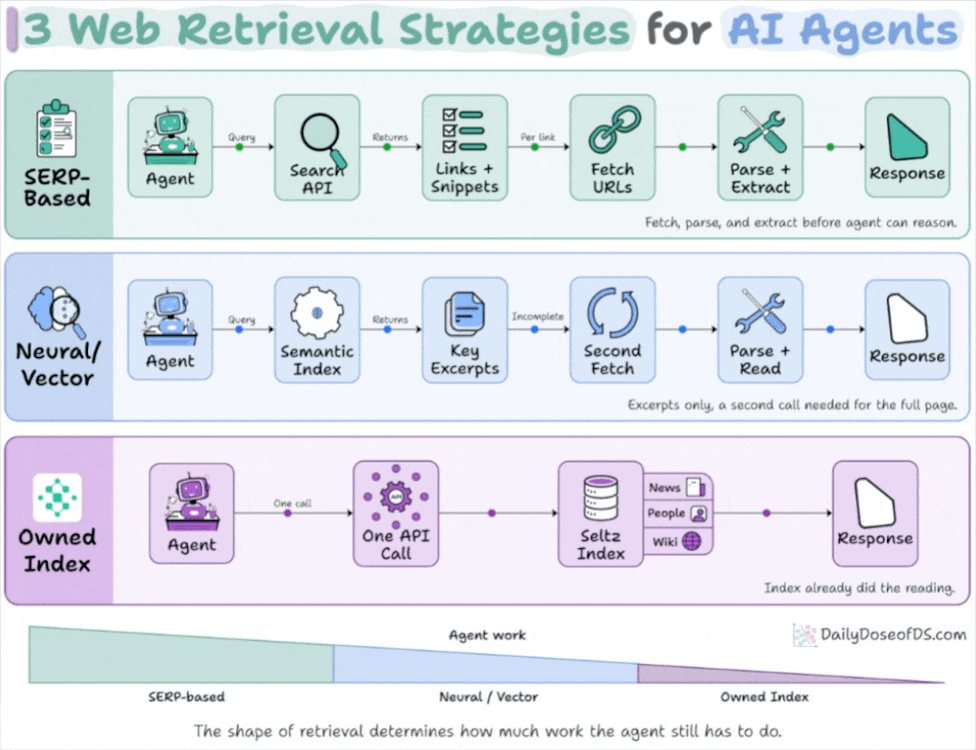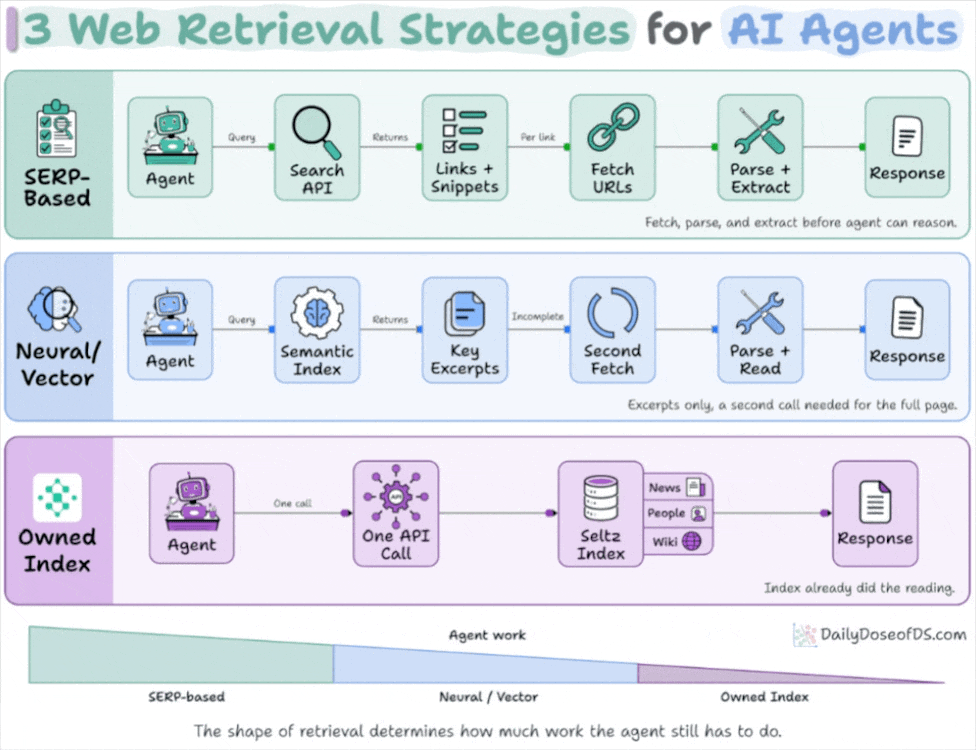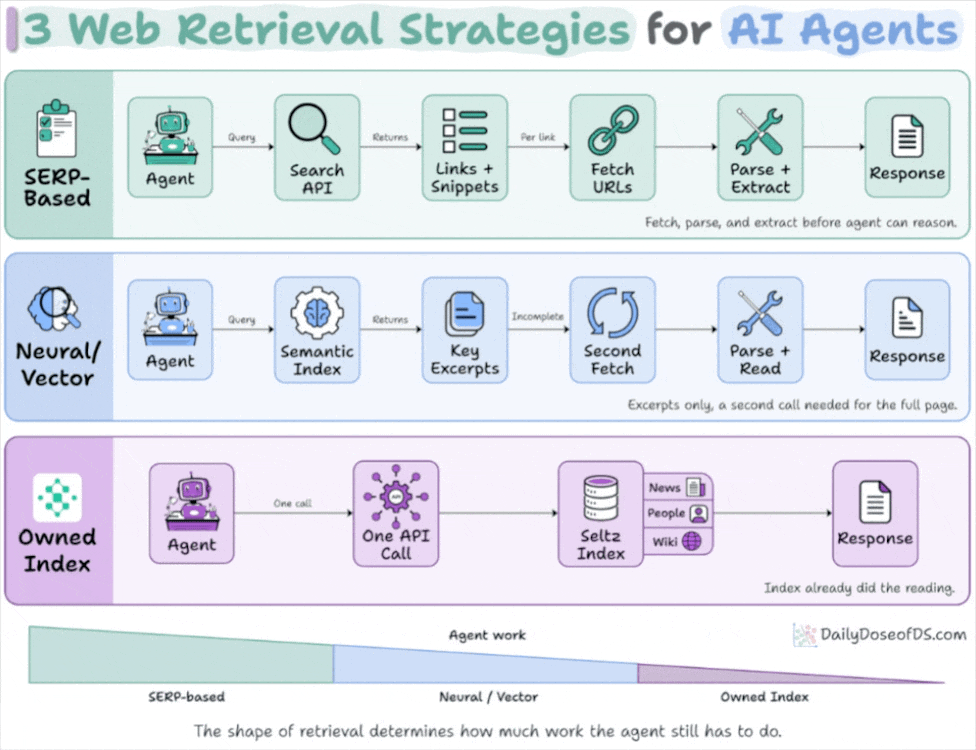
Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
1 minute a day. The AI essentials.
200+ sources · Email / LINE / Slack