Summaries like this, in your inbox every morning.
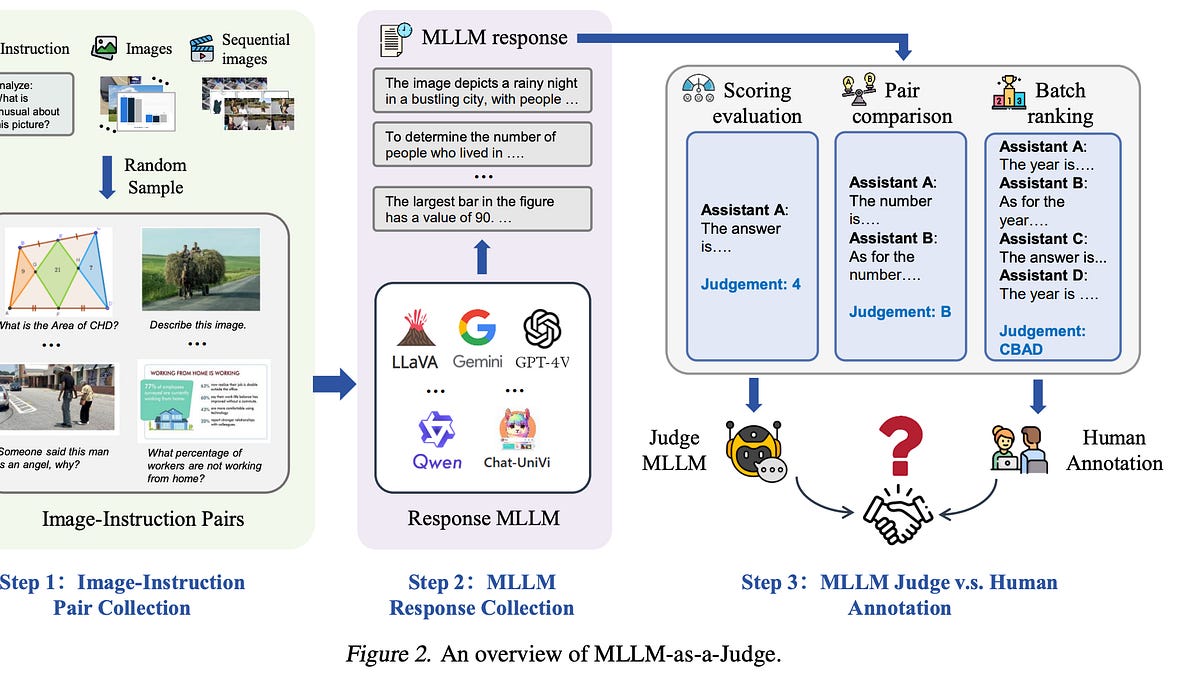
Sign up free →What happened: Studies on Multimodal LLM-as-a-Judge—AI systems designed to grade responses from other AI models—found that while these judges work reasonably well at picking the best answer from multiple options, they still show significant gaps in scoring and ranking tasks. The judges also exhibit biases (position bias, length bias, self-preference), hallucinations, and inconsistencies. A specialized video-judging model showed that smaller judges can match much larger general-purpose models when trained specifically for a task.
Why it matters: Companies deploying AI agents and multimodal systems (those that handle text, images, and video together) need reliable ways to automatically catch low-quality outputs before they reach users. Human evaluation doesn't scale; AI judges offer a potential solution. However, the research shows these judges are not ground truth—they require the same careful calibration and quality control that the systems they evaluate do, meaning teams must first verify that AI judges actually agree with human experts on their own definitions of quality.
What to watch: The VideoJudge research demonstrated that genuinely multimodal judges (those that can see video directly) outperform text-only judges that only read video descriptions, and that longer reasoning chains cannot substitute for actual visual understanding. This suggests companies choosing between building specialized judges versus repurposing general-purpose models will need to account for the modality mismatch in their deployment decisions.
No comments yet. Be the first to share your thoughts!
Log in to join the discussion




Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
5 minutes a day. The AI essentials.
200+ sources · Email / LINE / Slack