Summaries like this, in your inbox every morning.
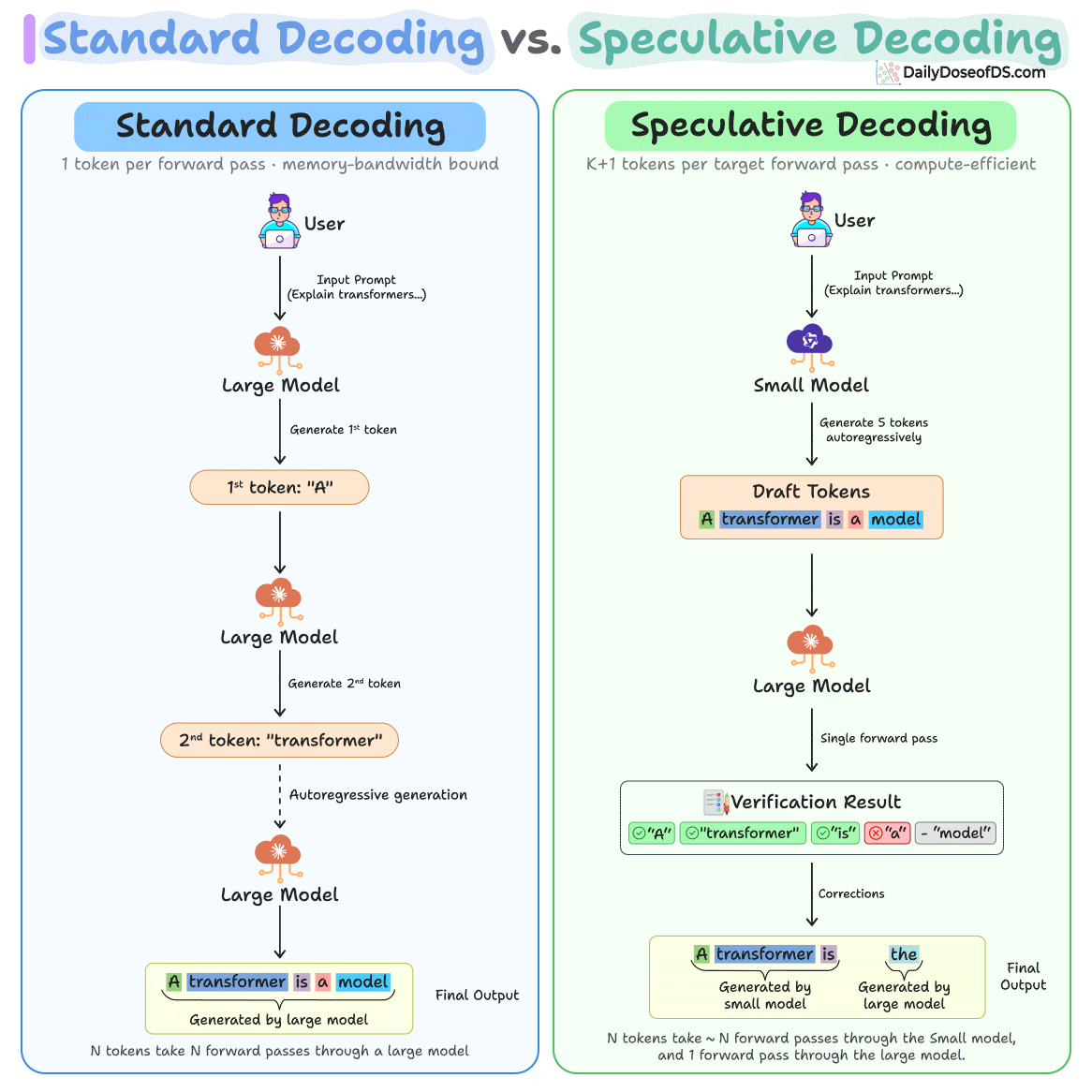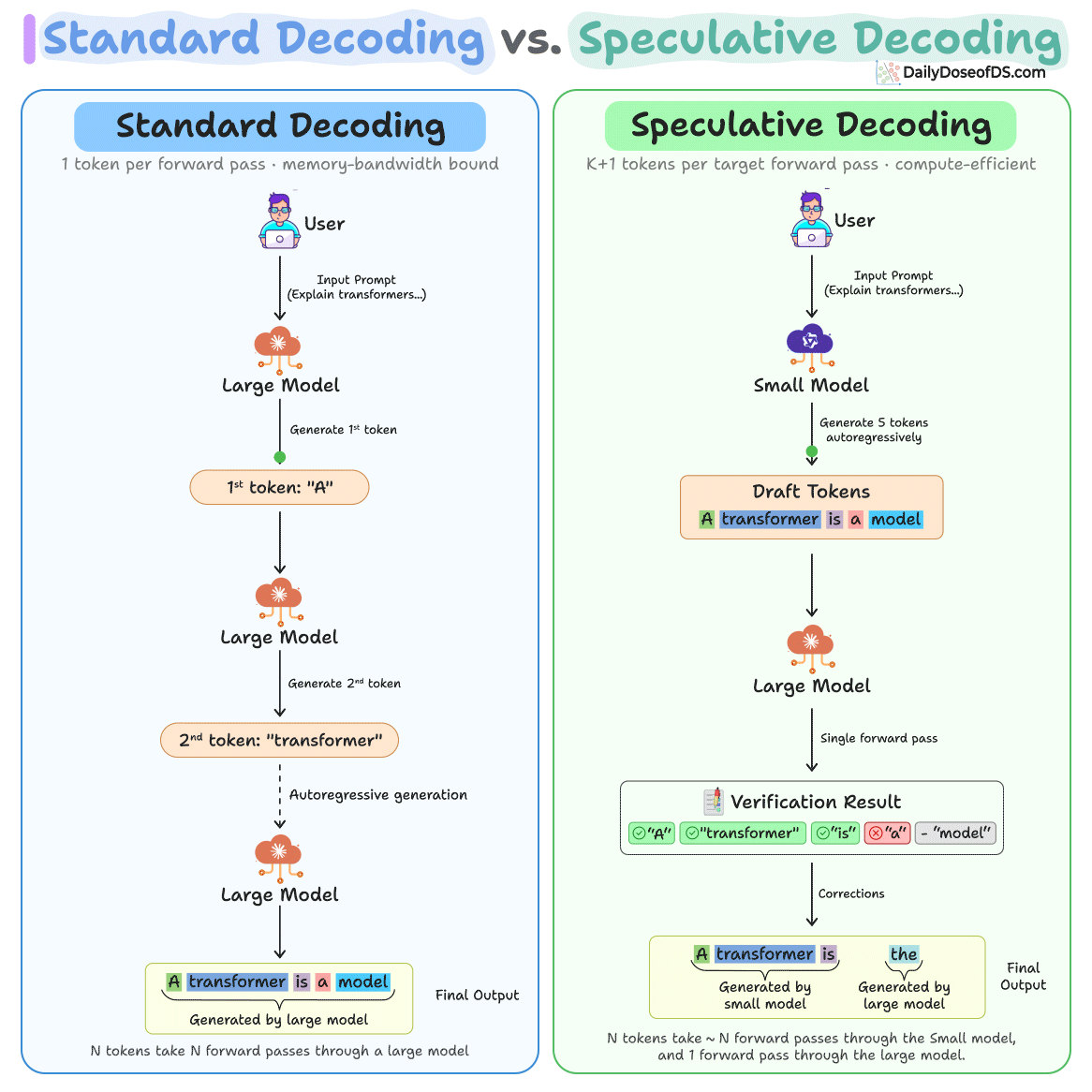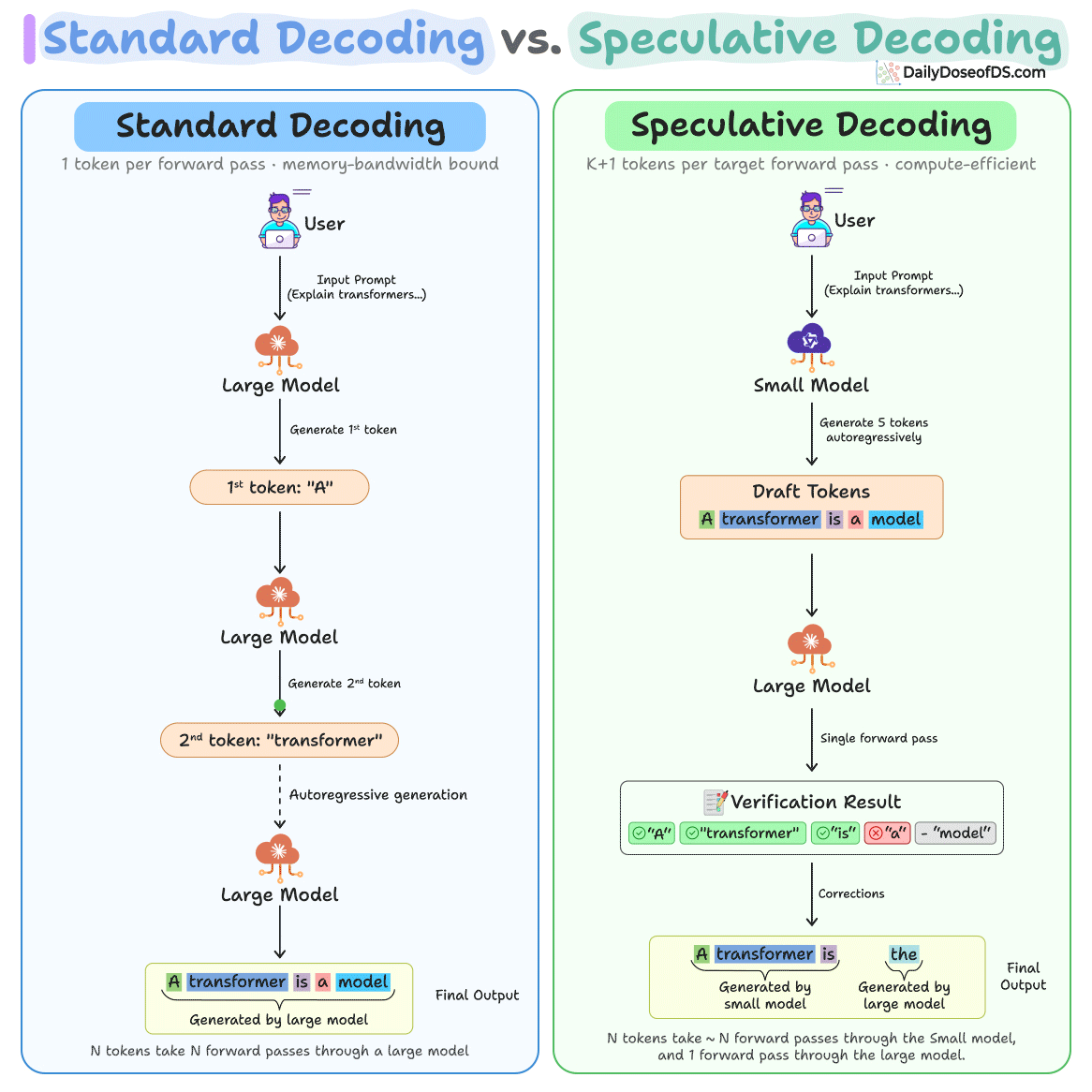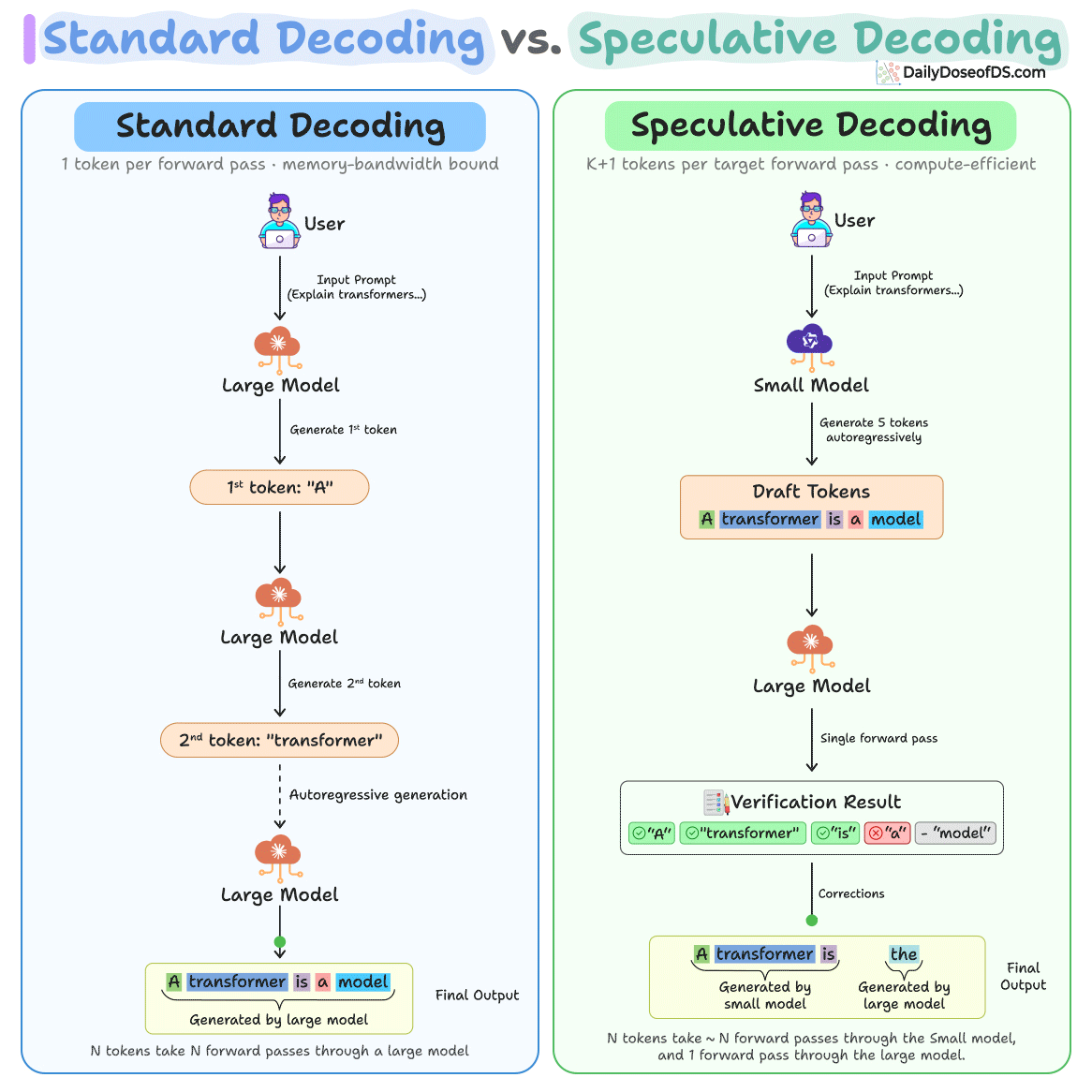
Sign up free →Speculative decoding works by having a small model (10–100x smaller than the target) generate K candidate tokens, then a large model verifies all K tokens in a single forward pass before accepting or rejecting each token. Google uses this in AI Overviews to serve over a billion Search users; Anthropic, Meta, and major inference providers use it to reduce latency at scale.
Same-tokenizer pairs (draft and target models sharing a tokenizer) achieve 1.5–3x speedup, while cross-tokenizer pairs achieve 1.5–1.9x speedup. For example, Llama 3.2 1B as drafter with a larger target model achieved 2.31x speedup, while Llama 3.1 8B achieved 2.08x despite higher token acceptance.
Emerging variants like EAGLE (trains a lightweight head on the target model's hidden states), Medusa (adds multiple prediction heads), and self-speculative decoding (LayerSkip, SWIFT—uses the target model's own early layers as drafter) aim to eliminate the need for a separate draft model or extra training.
No comments yet. Be the first to share your thoughts!
Log in to join the discussion




Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
1 minute a day. The AI essentials.
200+ sources · Email / LINE / Slack