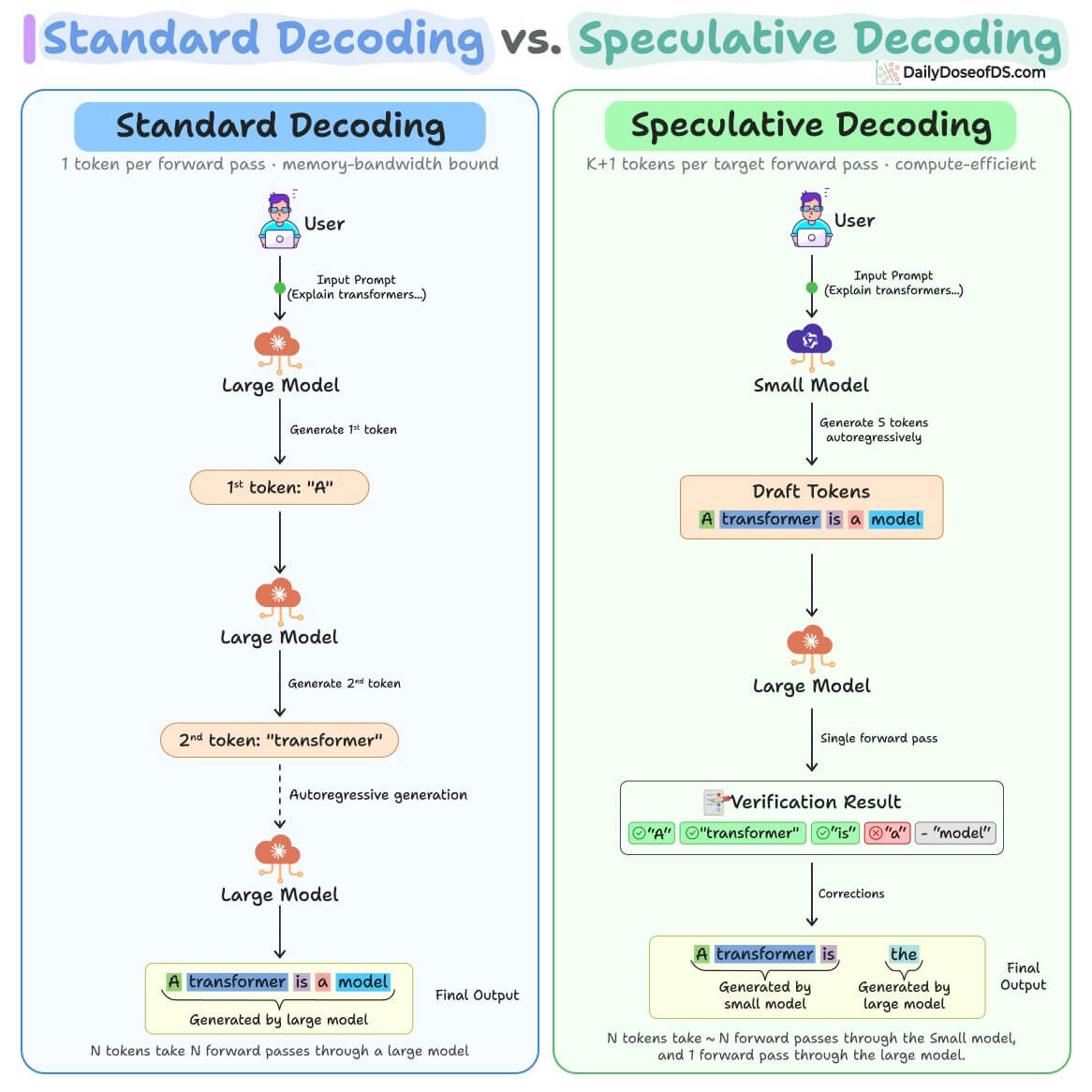
Modal が新しい DFlash ドラフトモデルをリリースし、推測デコーディングによる推論速度の上限を従来の 2~3 倍から大幅に超える水準へ引き上げました。Qwen 3.5 122B-A10B では 1000 トークン/秒以上の速度を達成し、従来の 250 トークン/秒から 4 倍以上高速化しています。ブロック拡散方式により複数トークンを並列に予測し、ターゲットモデルの内部表現を活用することで、トークン採用率が大幅に向上した結果です。
こういう要約が、毎朝あなたのメールに届きます。
無料で登録 →何が起きたか
Modal が新しい DFlash ドラフトモデルを Qwen モデル向けにリリースしました。従来の推測デコーディングは 1 トークンずつ予測する方式で 2~3 倍の速度上限に留まっていましたが、DFlash はブロック拡散モデルを使って複数トークンを一度に並列予測するため、この上限を超えることができます。Qwen 3.5 122B-A10B では 250 トークン/秒から 1000 トークン/秒以上に高速化しました。
なぜ重要か
推論処理の高速化は、AI サービスの応答時間短縮やコスト削減に直結するため、LLM を実運用するビジネスにとって重要な課題です。DFlash モデルが実データに基づいて訓練されているため、提案トークンの採用率が baseline の 3 から 9 以上に向上し、より実用的な速度向上が実現できるとみられます。
注目点
DFlash ドラフトモデルは既に vLLM、SGLang、Transformers に統合済みであり、HuggingFace で Qwen および他のモデルファミリー向けに提供されています。
まだコメントがありません。最初のコメントを投稿しましょう!
ログインして議論に参加




200以上のソースから厳選したAIニュースを毎日無料でお届けします。
無料で始める登録無料・30秒で完了・いつでも解除できます
毎朝5分、AIの要点だけ。
200媒体以上・Email/LINE/Slack 対応