Summaries like this, in your inbox every morning.
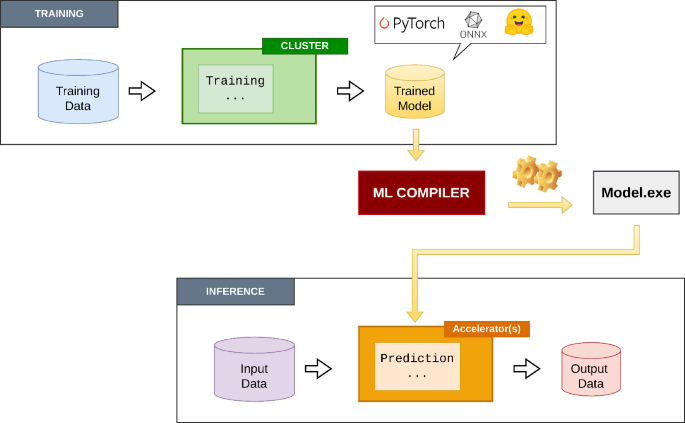
Sign up free →Study evaluates four major ML compiler tools—PyTorch's torch.compile (JIT-based), NVIDIA TensorRT, Google's XLA, and ONNX Runtime (AOT)—benchmarking them against state-of-the-art LLMs including TinyLlama-1.1B-Chat-v1.0 and Llama-2-7b-chat-hf to assess performance, productivity, and portability tradeoffs.
AOT (Ahead-Of-Time) TensorRT workflows consistently yield the highest throughput for low-precision formats, while multi-target approaches like PyTorch's torch.compile prioritize device-portability at the expense of raw performance and may yield no speedup for LLM inference.
The research identifies no universally optimal compilation workflow; choice depends on priorities: TensorRT/TensorRT-LLM for consistent performance gains across architectures and LLMs, ONNX for device-portability, or torch.compile for development agility out-of-the-box.
AI-summarized, only the topics you pick — one digest a day via Email, Slack, or Discord.
Free · takes 30 seconds · unsubscribe anytime
No comments yet. Be the first to share your thoughts!
Log in to join the discussion




Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
1 minute a day. The AI essentials.
200+ sources · Email / LINE / Slack