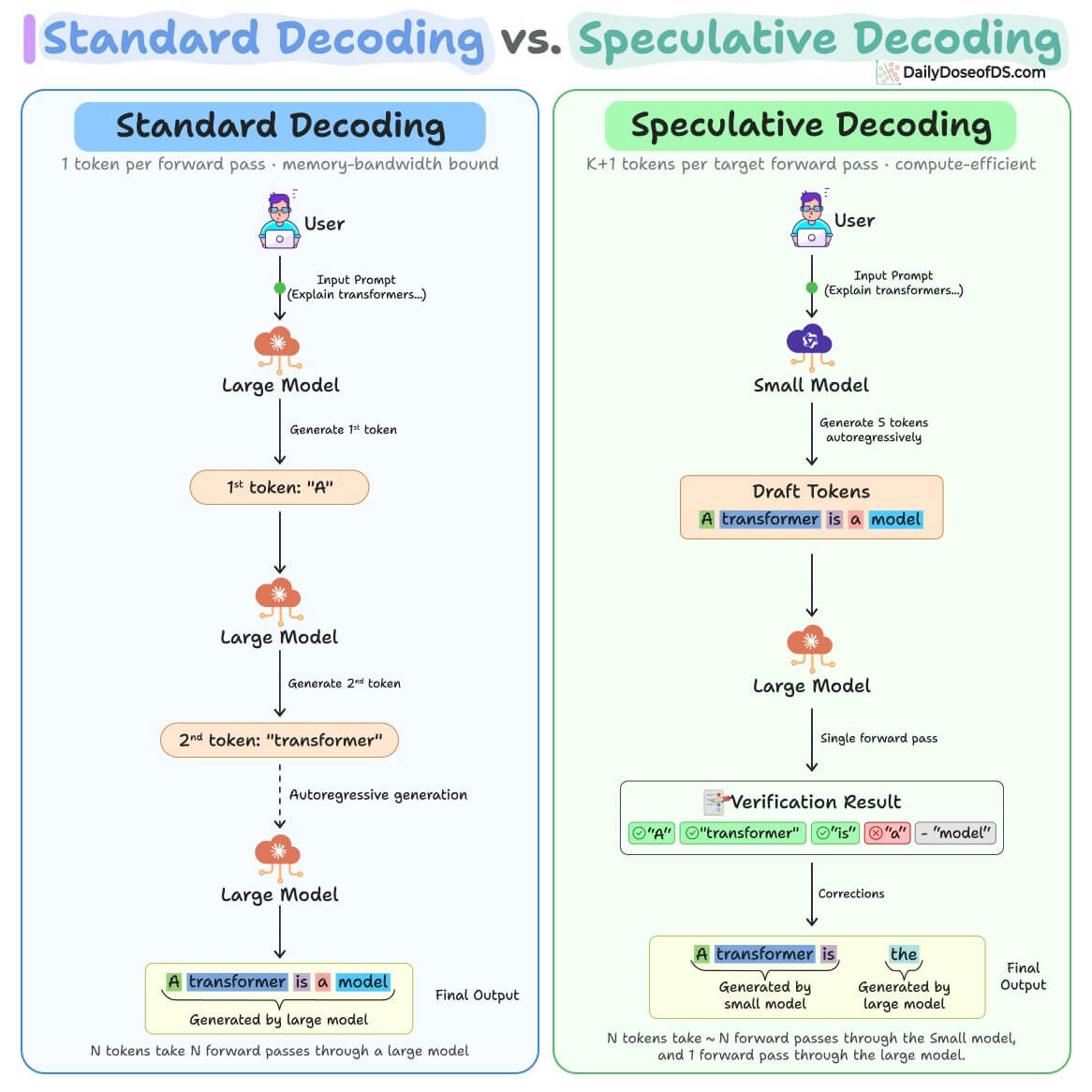
Modal released new DFlash draft models that accelerate AI inference by denoising entire blocks of tokens in parallel rather than one at a time, and by leveraging the target model's internal context representations. This overcomes a historical 2–3× speedup ceiling in speculative decoding; Qwen 3.5 122B-A10B now reaches over 1000 tokens/sec, up from 250 without speculation.
Summaries like this, in your inbox every morning.
Sign up free →What happened
Modal released DFlash draft models for Qwen AI models that use block diffusion instead of traditional sequential token generation. Running Qwen 3.5 122B-A10B with these drafters reached over 1000 tokens/sec on a B200, compared with 250 tokens/sec without speculation.
Why it matters
Speculative decoding has been capped around 2–3× speedup because the small draft model that proposes tokens became the bottleneck. DFlash breaks past this by denoising an entire block of tokens in parallel, and by using the target model's own internal representations to guide drafting, which raises acceptance length from a baseline of 3 to over 9.
What to watch
The DFlash draft models are already integrated with vLLM, SGLang, and Transformers, with draft models available on HuggingFace for Qwen and several other model families. Acceptance length maps nearly linearly to speedup—at length 8, Qwen 3.5 27B achieved 5.62× speedup on one B200.
No comments yet. Be the first to share your thoughts!
Log in to join the discussion




Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
5 minutes a day. The AI essentials.
200+ sources · Email / LINE / Slack