Summaries like this, in your inbox every morning.
Sign up free →Context engineering—deciding what information enters the AI agent's context window, what gets compressed, what gets retrieved on demand, and what gets dropped—addresses production failures caused by mismanaged context rather than model limitations.
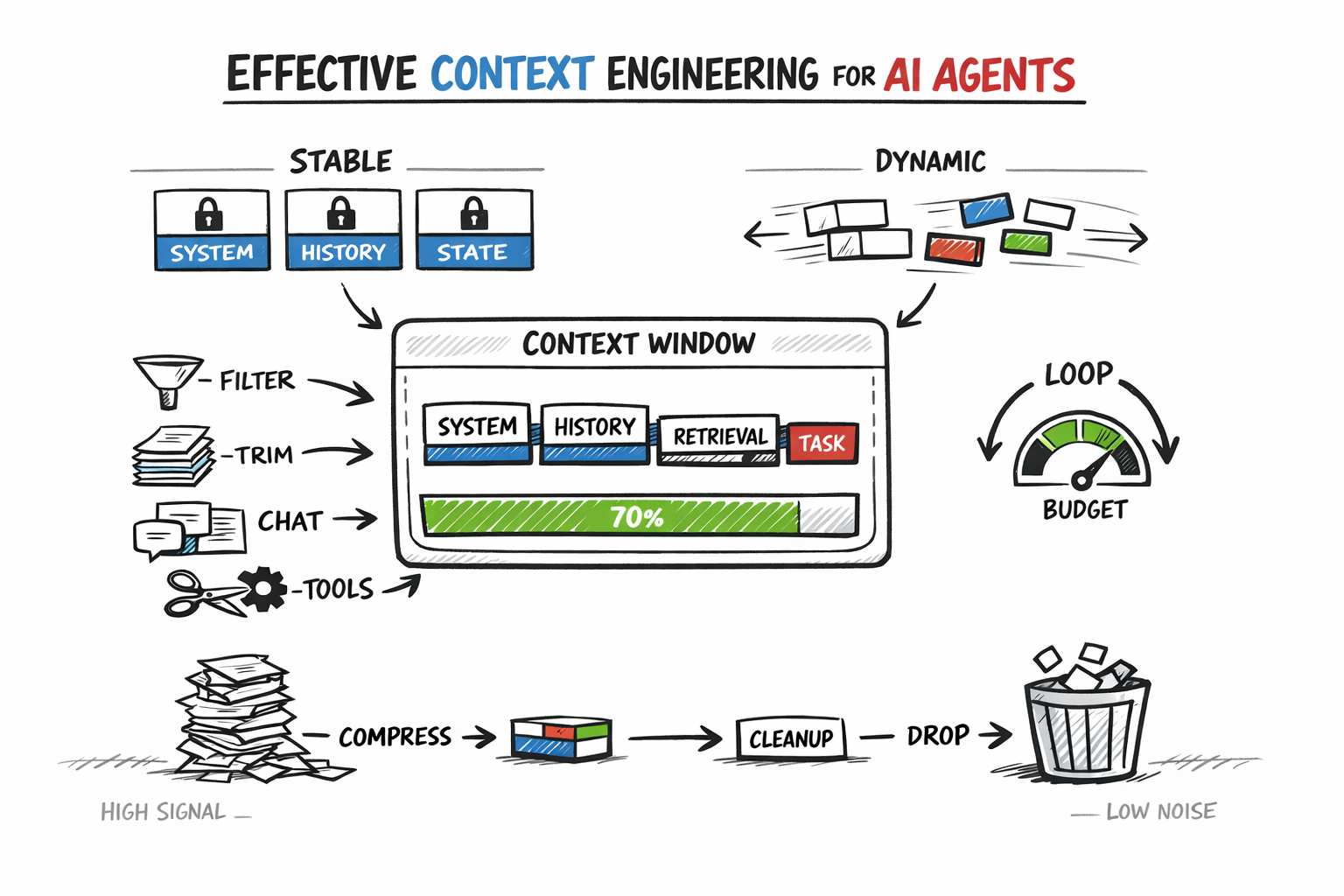
The approach separates static context (system instructions, tool schemas, fixed rules placed at the front for prefix caching) from dynamic context (current user input, recent tool outputs, retrieved documents in the variable suffix), implemented via a two-pass context assembly pipeline to simplify debugging and reduce computational cost.
Conversation history management uses strategies like recency truncation (keeping only the last N turns) to avoid context bloat and context poisoning (where earlier mistakes are preserved and treated as truth), with a stronger method being anchored iterative summarization that continuously updates a structured session-state document.
Retrieval should be designed as a budget decision: post-retrieval filtering (scoring and selecting relevant results before injection) is cited as one of the highest-leverage optimizations, and agents can either invoke retrieval automatically before every turn or control it as a tool when recognizing a need, with tradeoffs between simplicity and targeted query precision.
No comments yet. Be the first to share your thoughts!
Log in to join the discussion




Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
1 minute a day. The AI essentials.
200+ sources · Email / LINE / Slack