Summaries like this, in your inbox every morning.
Sign up free →A new post-training algorithm called Distribution Fine Tuning (DFT) was created to address LLM text that overuses certain tokens and phrases. DFT makes model outputs better match the training distribution, improving Maximum Mean Discrepancy (MMD) by 49% and Judge Model Quality (JMQ) by 63% compared to supervised fine-tuning (SFT).
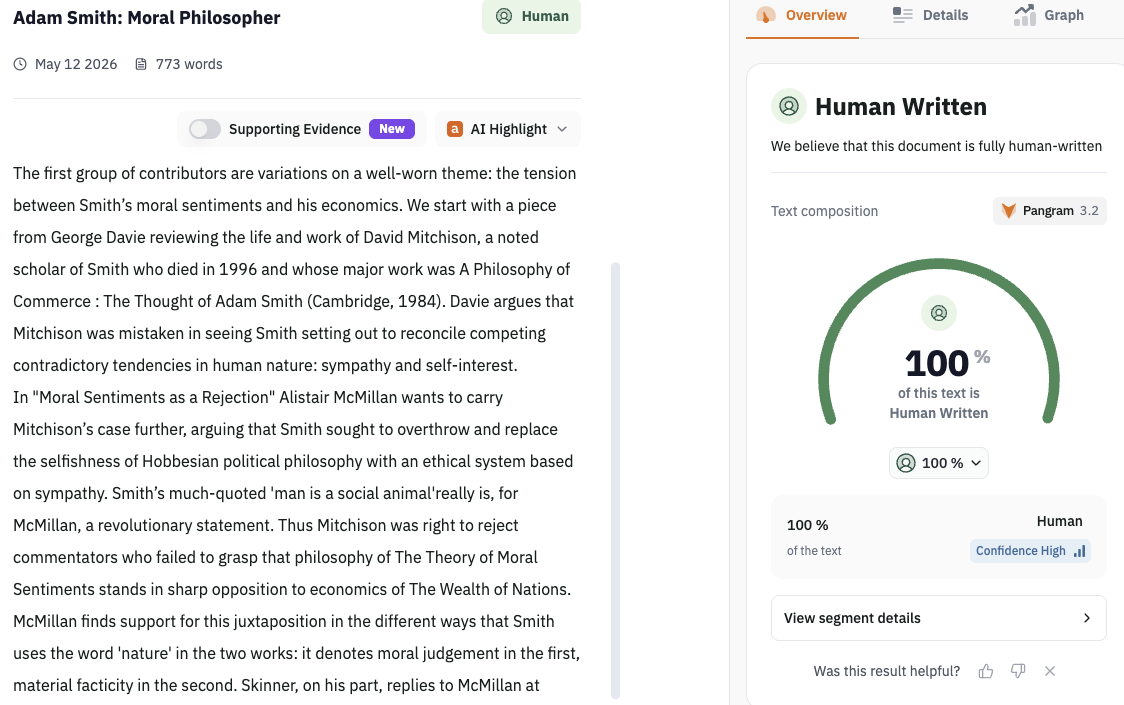
The algorithm optimizes at the distribution level rather than individual samples. A demo with a 14B parameter model is available at https://dft.rosmine.ai/, and outputs from models trained with DFT scored as 100% human written by Pangram AI detector on a sample of 100 outputs.
Compared to SFT baselines, DFT-trained models improve creativity scores by +164%, coherence by +28%, clarity by +16%, and meaningful detail by +146%, while eliminating overused 'slop signs' like excessive emdashes or repetitive phrases like 'it's not X, it's Y'.
AI-summarized, only the topics you pick — one digest a day via Email, Slack, or Discord.
Free · takes 30 seconds · unsubscribe anytime
No comments yet. Be the first to share your thoughts!
Log in to join the discussion



Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
1 minute a day. The AI essentials.
200+ sources · Email / LINE / Slack