こういう要約が、毎朝あなたのメールに届きます。
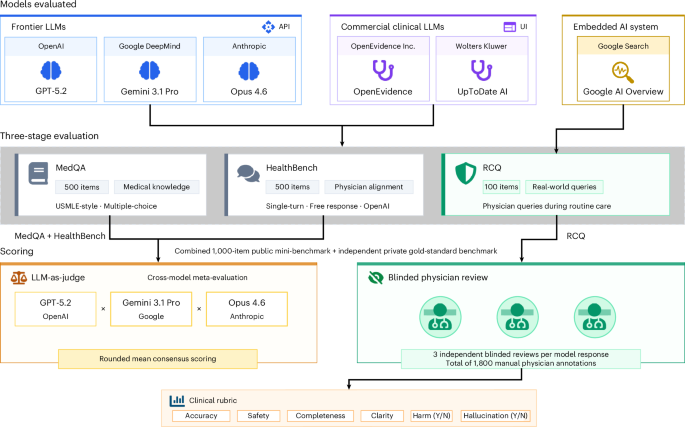
無料で登録 →何が起きたか:医療専門AI(OpenEvidenceとUpToDate Expert AI)と、GPT-5.2、Gemini 3.1 Pro、Claude Opus 4.6といった汎用言語モデルを3段階で比較評価しました。医学知識を問うMedQA500問ではGeminiが97.4%の精度で最高となり、OpenEvidenceの89.6%、UpToDateの88.4%を上回りました。実際の医師の質問100件を12人の米国医師がブラインド評価した「実臨床クエリ」ベンチマークでも、汎用モデルが医療専門ツールを上回りました。
なぜ重要か:医療専門AIツールは、その仕組みや学習方法が非公開のまま医療現場に導入されつつあります。本研究は、ドメイン特化と謳われた医療AIが、実際には一般向けの最新モデルより性能が低い可能性を示唆しており、医療現場での安全性評価の重要性を指摘しています。
注目点:実臨床クエリベンチマークでは、医師たちによる1,800件の模型・質問評価が行われました。研究は、臨床現場のAIツール導入前に独立した実世界評価が必要であることを強調しています。
まだコメントがありません。最初のコメントを投稿しましょう!
ログインして議論に参加





200以上のソースから厳選したAIニュースを毎日無料でお届けします。
無料で始める登録無料・30秒で完了・いつでも解除できます
毎朝5分、AIの要点だけ。
200媒体以上・Email/LINE/Slack 対応