Summaries like this, in your inbox every morning.
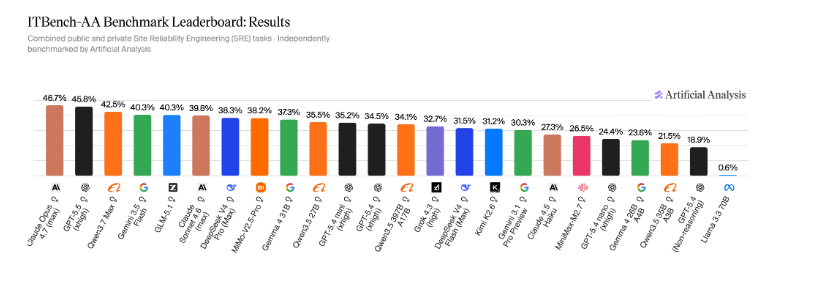
Sign up free →Artificial Analysis and IBM Software Innovation Lab released ITBench-AA, evaluating frontier AI models on agentic enterprise IT tasks starting with Site Reliability Engineering (SRE)—diagnosing Kubernetes incidents by reading logs, tracing dependencies, and identifying root-cause entities. Claude Opus 4.7 (Adaptive Reasoning, Max Effort) leads at 47%, followed by GPT-5.5 (xhigh) at 46% and Qwen3.7 Max at 42%.
The benchmark comprises 59 SRE tasks (40 public, 19 held-out) where models run in a sandboxed harness with shell access to incident snapshots. Scoring uses average precision at full recall: models must identify all ground-truth root causes or score 0.0 for that task repeat; if successful, they receive a precision score equal to true positives divided by true positives plus false positives.
All frontier models score below 50%, making ITBench-AA SRE one of the least saturated agentic benchmarks. Turn counts vary nearly 3x with no correlation to accuracy: GPT-5.5 (xhigh) averages 31 turns at 46%, while Gemini 3.1 Pro Preview averages 83 turns at 30%. Among open-weights models, GLM-5.1 (Reasoning) leads at 40%, tied with Gemini 3.5 Flash (high).
The benchmark and leaderboard are available at the ITBench-AA HuggingFace repo and artificialanalysis.ai/evaluations/itbench-aa; the Stirrup reference harness is open-source.
AI-summarized, only the topics you pick — one digest a day via Email, Slack, or Discord.
Free · takes 30 seconds · unsubscribe anytime
No comments yet. Be the first to share your thoughts!
Log in to join the discussion




Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
1 minute a day. The AI essentials.
200+ sources · Email / LINE / Slack