
Summaries like this, in your inbox every morning.
Sign up free →What happened
Researchers from MIT, Harvard University, TU Munich, Greenshoe Inc., Intel, and AWS AI Labs created BEAVER, a dataset containing 9128 queries spanning 812 tables across 19 diverse domains. Of these, 7978 queries are publicly released, while the remaining portion is held out as a private test set. The dataset includes annotations for five subtasks: multi-table retrieval, join key detection, column mapping, domain knowledge extraction, and query decomposition.
Why it matters
Text-to-SQL translation—converting natural language questions into database queries—is a critical task for enterprise data analysis. By providing a large, diverse benchmark with real-world database schemas from private organizations and fine-grained annotations across multiple subtasks, the dataset enables researchers and companies to systematically evaluate and improve AI models on this practical problem.
What to watch
The dataset distinguishes between three categories of queries: complex queries without domain knowledge, domain-specific queries with minimal complexity, and domain-specific complex queries. This structure allows evaluators to measure performance across different levels of difficulty and business relevance. The 7978 public queries are available for research, while the private test set remains for independent evaluation.
AI-summarized, only the topics you pick — one digest a day via Email, Slack, or Discord.
Free · takes 30 seconds · unsubscribe anytime
No comments yet. Be the first to share your thoughts!
Log in to join the discussion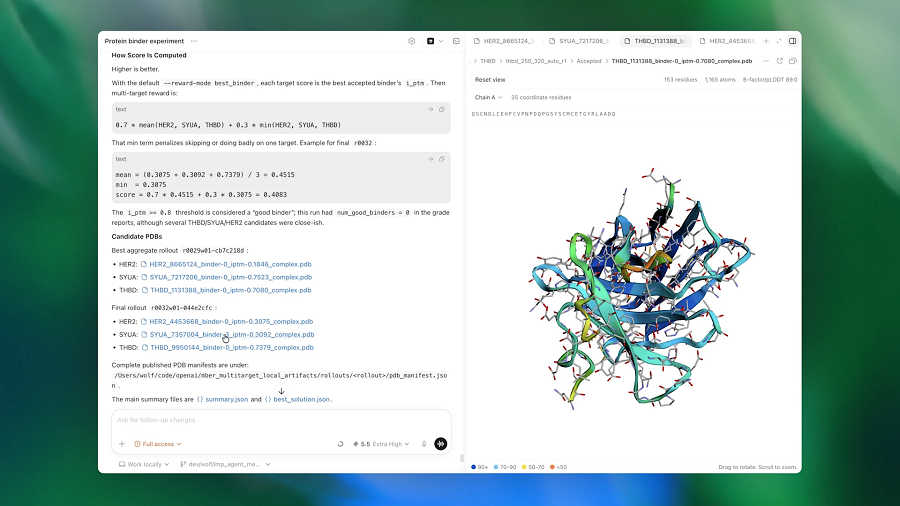





Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime