Summaries like this, in your inbox every morning.
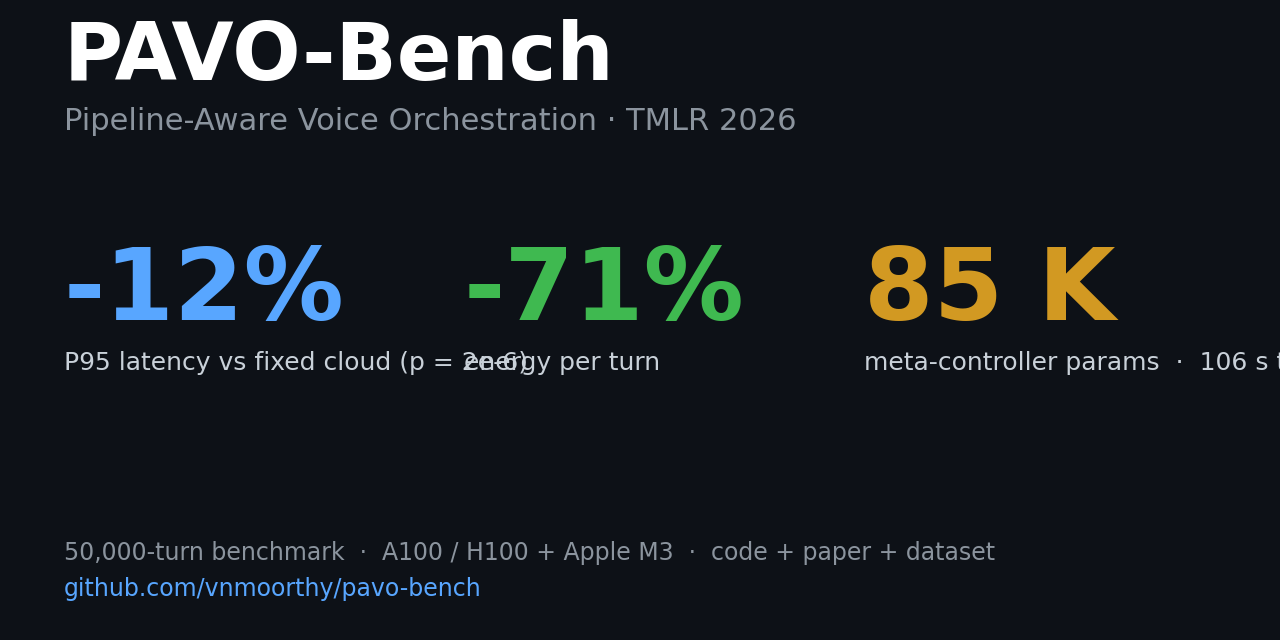
Sign up free →Researchers at University of Pennsylvania and Google released PAVO-Bench, a 50,000-turn voice interaction dataset (40K train / 10K test) with complexity labels on HuggingFace, plus a trained tiny meta-controller (85,041 parameters) that decides per turn whether to route ASR → LLM → TTS calls to cloud or edge.
The router characterizes inter-stage coupling: Gemma2 2B quality drops from 0.825 → 0.585 as ASR word-error rate crosses 2% (n=200 per WER level), meaning downstream LLM performance depends on upstream ASR configuration. Hard-constraint masking reduces coherence-failure rate from 7.1% → 0.9% (7.9× reduction) at +110 ms median latency cost.
Against a fixed-cloud baseline on LibriSpeech, PAVO achieved P95 end-to-end latency −10.3% (−167 ms, p = 2×10⁻⁶), median latency −34%, and energy per turn −71%, measured on NVIDIA H100 and Apple M3 8 GB across Llama 3.1 8B, Mistral 7B, and Gemma2 2B.
Code, trained weights, and all 5,430 coupling calibration measurements are open-sourced; full reproduction takes roughly half a day on an H100; training-only reproduction runs in ~2 minutes on a single A100.
No comments yet. Be the first to share your thoughts!
Log in to join the discussion




Get curated AI news from 200+ sources delivered daily to your inbox. Free to use.
Get Started FreeFree · takes 30 seconds · unsubscribe anytime
1 minute a day. The AI essentials.
200+ sources · Email / LINE / Slack