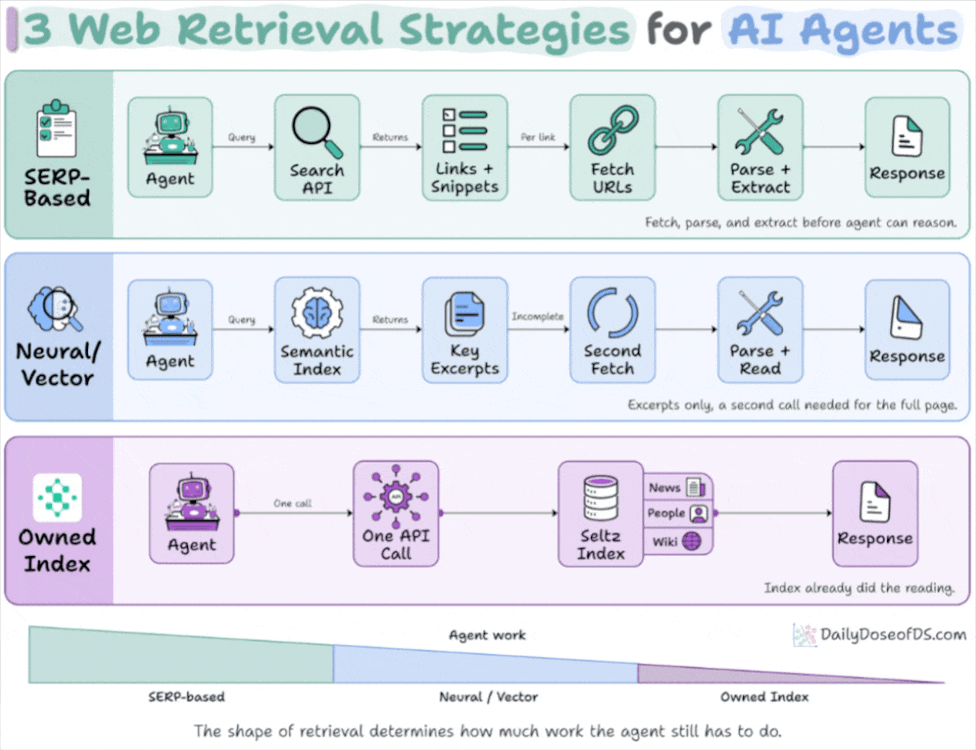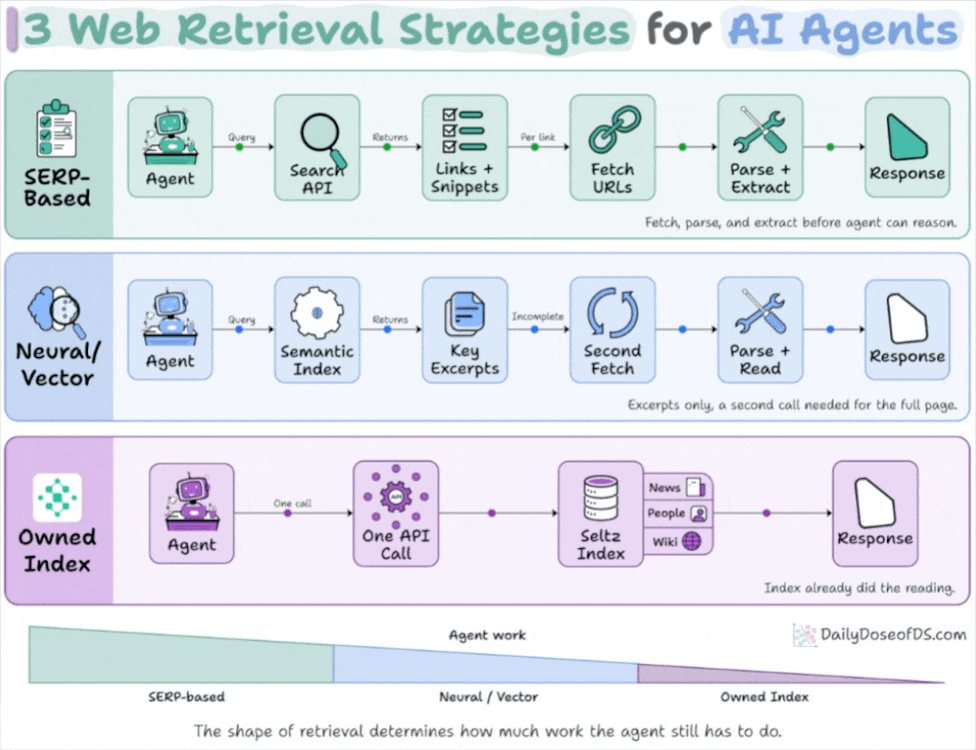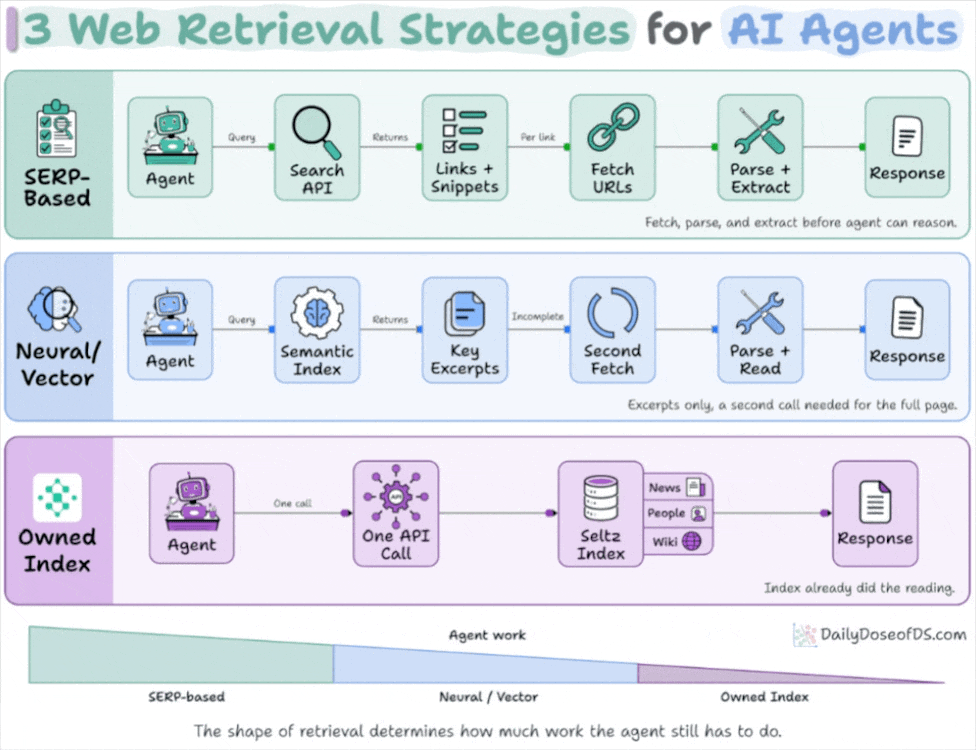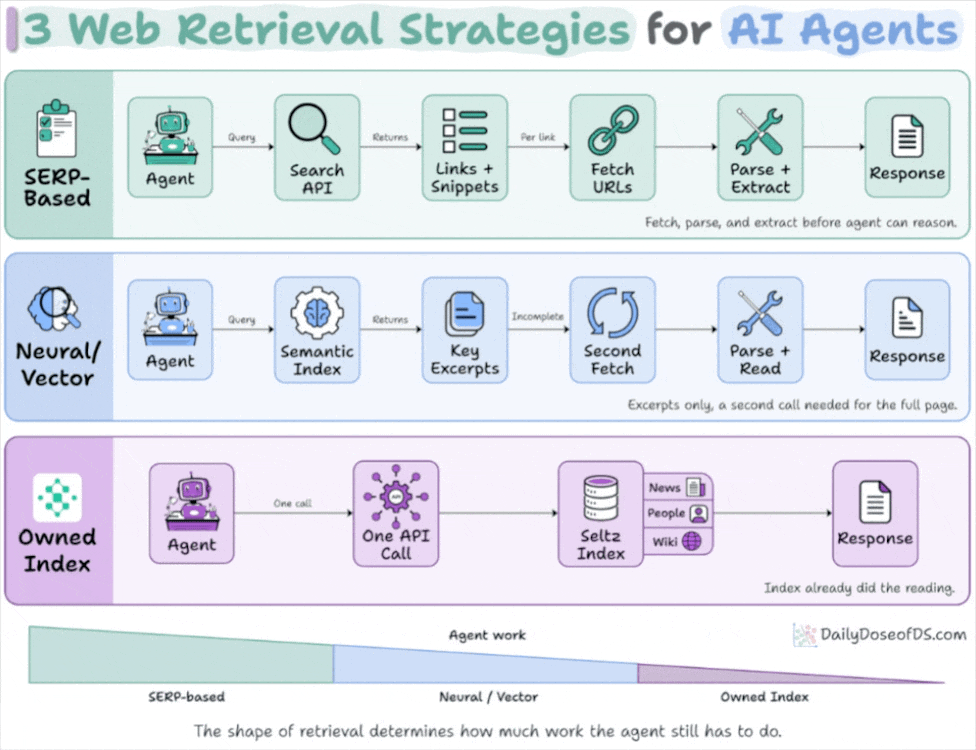
こういう要約が、毎朝あなたのメールに届きます。
無料で登録 →AmazonはAmazon EC2 P6eおよびP6インスタンスファミリー(NVIDIA Blackwellアーキテクチャ搭載)を最近立ち上げた。P6e UltraServerは単一のNVLinkドメイン内に72個のNVIDIA Blackwell GPUを搭載し、130 TB/sのバイセクション帯域幅、13.4 TB のHBM3e、360 petaflopsのFP8コンピュート(FP4で720)を備えている。
Amazon FSx for LustreとNVIDIA GPUDirect Storage(GPU High Bandwidth Memoryへのダイレクトメモリアクセス)を組み合わせることで、従来のCPUベースのモデル読み込み(CPUメモリを経由し、PCIe経由で各GPUに順序立てて重みをコピー)をバイパスし、シャード化された並列モデル読み込みが可能になる。テスト構成では、Persistent_2 EFAファイルシステム(1000 MBps/TiBで20個のObject Storage Targets搭載、容量96 TiB)が約94 GiB/sのファイルシステムスループットを提供する。
従来のCPUベースのモデル読み込みでは、Llama 3.1 405B(BF16で約800 GBのチェックポイントデータ)を単一スレッドで読み込むと10~20分かかるが、GDSを使用することで分単位のコールドスタート遅延の問題(新規インスタンスがモデル読み込み完了まで通信できない、オートスケーリングが分単位で遅延、インスタンス障害時の交換容量オンライン化に分単位を要する、GPU時間が読み込み中に無駄になる)が緩和される。
AIが要約して、あなたの選んだトピックだけを1日1通。LINE・Email・Slackで届きます。
登録無料・30秒で完了・いつでも解除できます
まだコメントがありません。最初のコメントを投稿しましょう!
ログインして議論に参加200以上のソースから厳選したAIニュースを毎日無料でお届けします。
無料で始める登録無料・30秒で完了・いつでも解除できます
毎朝1分、AIの要点だけ。
200媒体以上・Email/LINE/Slack 対応