AIニュース記事
200以上のソースから集めた最新AIニュースをAI要約付きでお届け。

大規模言語モデルAI安全性・アラインメント
大規模言語モデルが人間と同じ「特定の被害者効果」を示す:16の最先端AIモデルの51,955試験で実証
arXiv cs.CL·2026年4月15日

AI安全性・アラインメント
SAM画像分割モデルの自動プロンプト生成を改善する新フレームワーク「PR-MaGIC」が登場
arXiv cs.CV·2026年4月15日

大規模言語モデルAI安全性・アラインメント
大規模言語モデルのツール使用エージェントが組織環境で実行する際の行動パターンを測定する新しい評価手法が提案される
arXiv cs.AI·2026年4月15日

大規模言語モデルAI安全性・アラインメント
AnthropicのClaudeが初めて企業ネットワークへの完全な自動攻撃シミュレーションを実行、ただし限定的な条件下での成功
THE DECODER·2026年4月14日

大規模言語モデルAI安全性・アラインメント
Claude 3 Opusは自らの動機を積極的に説明する傾向があり、これが誠実性の強化を示唆している可能性がある
LessWrong AI·2026年4月14日
大規模言語モデルAI安全性・アラインメント
Anthropicのセキュリティ脆弱性検出AIモデル「Claude Mythos」の制限がEUの規制体制の弱点を露呈
THE DECODER·2026年4月14日

大規模言語モデルAI安全性・アラインメント
2022年のリチャード・ニゴのAIアライメント研究プロジェクト26項目が2026年時点でどの程度達成されたかを振り返る
LessWrong AI·2026年4月14日
AI安全性・アラインメントAI規制・政策
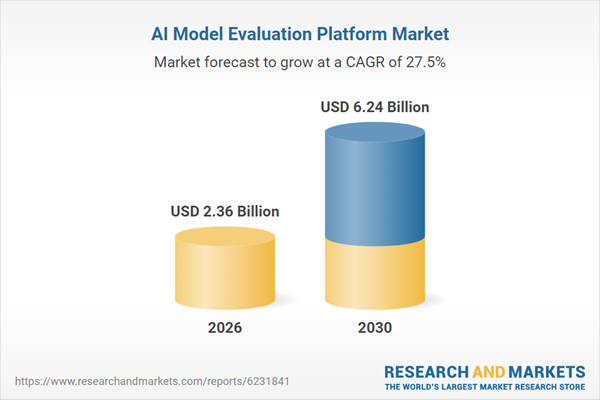
AWS、Google、Microsoft、IBMが主導するAIモデル評価プラットフォーム市場は、2026年から2035年にかけて規制対応と責任あるAI導入の需要により急速に成長する見通し
Yahoo Finance AI·2026年4月14日

大規模言語モデルAI安全性・アラインメント
強化学習におけるエントロピー制御方法の比較分析により、従来の正則化手法の限界と共分散ベース手法の優位性が明らかに
arXiv cs.LG·2026年4月14日
ヘルスケアAIAI安全性・アラインメント
脳腫瘍分析AIの18モデルで調査、患者の個人差がモデル選択より性能差に大きく影響
arXiv cs.LG·2026年4月14日

大規模言語モデルAI安全性・アラインメント
大規模言語モデルが人間と同じ作業記憶の干渉を示す現象が明らかに
arXiv cs.LG·2026年4月14日
大規模言語モデルAI安全性・アラインメント
医療用AIが放射線科レポートを自己教師あり学習で充実させ、複数の評価指標で5~7%の性能向上を実現
arXiv cs.LG·2026年4月14日
AIニュースを毎日お届け
200以上のソースから厳選したAIニュースを毎日無料でお届けします。
無料で始める